Готов поспорить, что многие из вас уже не представляют себе вечера без просмотра рекомендаций на YouTube или дороги на работу без подборок в Spotify. Стриминговые сервисы отлично знают наши вкусы, а интернет-магазины идеально подбирают товары, которые с высокой вероятностью придутся нам по душе.
Все это возможно благодаря рекомендательным системам – программам, которые на основе данных о пользователе подбирают для него релевантные продукты и услуги. Они давно и активно используются различными интернет-магазинами и стриминговыми сервисами. Так, согласно отчету McKinsey уже сейчас 35% того, что потребители покупают на Amazon, и 75% того, что они смотрят на Netflix, формируется благодаря рекомендациям, основанных на таких алгоритмах. И по прогнозам, эти цифры будут только расти.
Сегодня пользуются популярностью два типа рекомендательных систем: коллаборативная фильтрация и основанные на контенте.
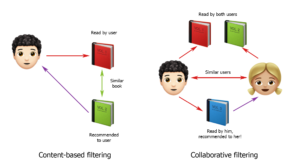
Коллаборативная фильтрация
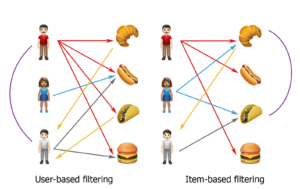
Коллаборативная фильтрация, или Collaborative Filtering, начала активное развитие в 90-х годах прошлого века. Ее основной принцип работы – генерировать рекомендации на основе данных о других пользователях с похожими интересами. Фильтрация бывает user-based и item-based.
В случае user-based основная задача алгоритма найти пользователей, чьи интересы максимально похожи на основе потребленных ими продуктов и выставленных оценок. Предположим, у нас есть пользователи Аня и Дима, которые купили газировку, батончик и чипсы. Игорь тоже любит газировку и батончики, значит ему нужно порекомендовать купить чипсы.
Item-based рекомендации рассматривают задачу с другой стороны: найти похожие объекты и посмотреть, как их оценивали до этого. Попробуем выяснить, нравятся ли Игорю чипсы. Мы знаем, что он любит газировку и батончики, значит ему понравятся чипсы.
Алгоритм коллаборативной системы должен найти пользователя, который оценил конкретный предмет, и посчитать коэффициент корреляции векторов их оценок всем предметам в базе данных. Для этого можно воспользоваться методом k-ближайших соседей, взять пользователей с самыми высокими коэффициентами корреляции и посмотреть, как они оценивали конкретный предмет. При этом важно разделить каждую оценку пользователей на его среднюю оценку, чтобы увеличить точность.
Основанные на контенте
В центре модели, основанной на контенте, стоит предмет. При этом совершенно не важно, как его оценивал пользователь. Важно знать любые свойства, которые могут охарактеризовать предмет: автор, жанр, страна, производитель и т.д. При этом важно понимать, что не все характеристики могут быть релевантными при выборе товара покупателем, поэтому не стоит увлекаться определением всех его свойств.
В последнее время именно модели, основанные на контенте, пользуются большой популярностью у создателей систем. Дело в том, что эту модель пользователю не нужно долго “обучать” своим предпочтениям, а создатели могут сразу приступить к рекомендациям товаров для пользователей. Но есть и обратная сторона медали. Скорее всего вы замечали, что когда искали в Google зимние ботинки, то потом по многим сайтам за вами “гоняется” реклама с предложением купить ботинки в каком-нибудь интернет-магазине. Чтобы уменьшить количество негативных отзывов о нерелевантности таких объявлений, разработчики дополняют алгоритм моделью, основанной на знаниях: они также не опираются на оценки пользователей, а учитывают только его профиль и профиль товара.
Проблема холодного старта
Когда для работы рекомендательной системы еще не накоплено достаточное количество данных, появляется так называемая проблема холодного старта. Это типичная ситуация, например, для нового или непопулярного товара. Если предмет оценили только Аня, Дима и Игорь, то такая оценка также не будет достоверной для корректной работы рекомендательной системы. В таких случаях рейтинги корректируют искусственно.
Например, оценку вычисляют не как среднюю по позиции, а как сглаженную среднюю. Так, при малом количестве оценок рейтинг предмета будет тяготеть к некой “безопасной средней”, а когда набирается достаточное количество реальных оценок становится достаточно, то искусственное усреднение отключается.
Вместо вывода
Для создания персонализированных рекомендаций существуют и другие подходы, однако они гораздо реже применяются на практике в современных системах. Как правило, методы основанные на контенте и коллаборативная системы достаточно, чтобы построить качественную рекомендательную систему. При этом важно, чтобы рекомендации были релевантны пользователям и они смогли бы доверять ей. Это может помочь любой компании, которая работает в интернете, предоставлять пользователям качественный контент, продукты в нужном месте и нужное время, а также увеличить эффективность бизнеса, снизить издержки на рекламу, увеличить средний чек и повысить рентабельность предприятия в целом.